You know – sometimes I wish Vectrex was a more “modern” machine. Modern in the sense of “every Vectrex behaves the same”.
I recently rediscovered, that not all Vectrex are equal – some are more equal, and some are even especially equal!
What am I talking about?
Cycle counting – as alway when optimizing (or while testing out what does work on one Vectrex, but doesn’t on another).
Some variances I/we found so far:
- buzz / no buzz -> sampled sound issue (can be heard)
- buzz/ no buzz -> cart line on cartridge port (can be experiences with different multi cards)
- differences in DAC speed (can be seen when changing integrator values while drawing (curved vectors)
- different “SHIFT speeds” (although today I might say different vector monitor cirquit speeds, which is more probable) – can be seen in Moon Lander (or VecFevers different string timings)
- VIA stalling (at different cycle offsets, see old post of mine on this blog)
- different “reaction” speed of mux/integration circuit (see below)
- different “wait” needed for y/z integration circuit (see below)
- different T1 timer “start times” (see below)
The last three are the ones that started to grow on me the last couple of days. As some of you may know I am in the (slow) process of programming a new game (name is Vectorblade btw). For that game I tried to put a lot on screen and do it fast.
(now it gets a little bit technical)
The typical sequence to draw a vector might go like this:
ldb #ypos ; 2
lda #0 ; 2
stb <VIA_port_a ; 4
sta <VIA_port_b ; 4
ldb #xpos ; 2
lda #1 ; 2
sta <VIA_port_b ; 4
stb <VIA_port_a ; 4
lda #SHITREG_POKE_VALUE ; 2
clrb ; 2
sta <VIA_shift_reg ; 4
stb <VIA_t1_cnt_hi ; 4
wait till timer t1 runs out
; 36
This for a starter is highly NOT optimized. The numbers denote the cycles needed for one line, the sum of all is 36 cycles, which is actually still not to slow.
A short summary in words (per line):
- load ypos to reg b
- load value for via port b to reg a
- store reg b (ypos) to DAC out
- set mux to y integrator and enable mux -> y value goes to y integrator
- load xpos to reg b
- load value for via port b to reg a
- disable mux, value in DAC will only go to x integrator
- store reg b (xpos) to DAC out
- load a propper SHIFT value (this is a pattern, and mostly it is $ff) to reg a
- clear register b
- write reg a the SHIFT, shifting will start and last 18 cycles, highest bit will “endure”, bit values go to ~BLANK
- write b (zero) to timer 1 hi, this starts the timer 1 (lo value of timer is scale). ~RAMP will be cleared as long as timer is running (vector beam is MOVING)
Additional knowledge:
- VIA PORT B and VIA PORT A are consecutive addresses (namely $d000 and $d001)
- 8 bit registers: reg A and reg B are internally connected such that register D = A*256+B (D is a 16 bit register)
- the 6809 is big endian (hi values are “further left” than low values)
With that knowledge, the first four lines from above could be written as:
ldd #ypos*256+0 ; 3
std <VIA_port_b ; 5
Which would save as 4 cycles (12 <-> 8) – Yeah!
Nay :-(.
This is what I called “different “reaction” speed of mux /integration circuit”. A vague guess – 90% of vectrex are ok with that. But there ARE vectrex which “hickup”.
Dumb thing – I want my program to run on all vectrex -> in order to circumvent, I have to chose an “in between”, following is OK on all (known) Vectrex:
ldd #ypos*256+0 ; 3
stb <VIA_port_a ; 4
sta <VIA_port_b ; 4
These sequence takes 11 cycles (losing 3 cycles – grrr).
Ok – we chewed that down – lets go on further optimizing, the next lines describe setting a value for the “x integrator”. Let us assume we did some setup in advance and do not need the lines:
ldb #xpos ; 2
lda #1 ; 2
because we “filled” the x register in advance with correct values, like
ldx #1*256 + xpos ; 3
Than as an optimization the first four lines could look like:
ldd #ypos*256+0 ; 3
stb <VIA_port_a ; 4
sta <VIA_port_b ; 4
stx <VIA_port_b ; 5
Saving at this point another 7 (12 <->5) cycles! – Yeah!
Nay :-(.
This is what I called “different “wait” needed for y/z integration circuit”. A vague guess – 90% of vectrex are ok with that. But there ARE vectrex which “hickup” with that. Some vectrex need two additional cycles between the “mux changes” (writing to VIA_PORT_B), and some even rarer Vectrex need 4 additional cycles! So to be save to run on all vectrex:
ldd #ypos*256+0 ; 3
stb <VIA_port_a ; 4
sta <VIA_port_b ; 4
nop ; 2
nop ; 2
stx <VIA_port_b ; 5
Another 4 cycles gone with the wind.
So we lost already 7 cycles per line because a very minor part of Vectrex behave badly!
You might say “phhht – 7 cycles, so what!”
That is 7 cycles PER drawn/moved vector!
Let’s only display 20 enemies in Vectorblade, each enemy might consist of 20 vectors than we are already at: 20*20*7 = 2800 cycles – nearly a 1/10th of the time I have for a 50Hz game.
Note also:
The degree of “mess up” if the Vectrex is prone to the above behaviour also depends on the value (high negative values) you are setting to the y integrator (and/or the value that was in the intgerator beforehand (thus -> the difference of values))
This is infuriating (and a challenge)…
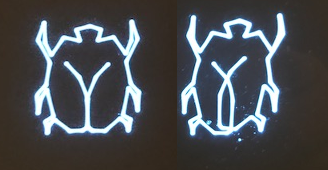
I have a Vectrex whose T1 timer starts (and stops) 2 cycles later than on my other Vectrex.
Often you would not notice the difference. With highly optimized hardware “accesses” this might drive you nuts! (see image above)
All my previous “SmartDraw” routines base on the fact, that a simple draw sequence takes “X” cycles. The smart draws do not WAIT actively (T1 interrupt check) till the timer is finished, but they “know” how much time is left – and do things in advance (setup next vector output etc).
With the things setup as they were everything is drawn fine if the objects have a scale of 9. That is (was) my optimal scale for printing, if I used a higher scale I need additional wait instructions since there is nothing left to prepare for the next vector – so cycles are “wasted” with idle waits.
So naturally ALL my sprites are designed to work with a scale of 9 – and drawing was at an optimum.
NOW I tested Vectorblade on that special machine for the first time (and I didn’t know it had a “delayed timer”) and all sprites look weird!
(Since the delay of 2 cycles resulted in the next vector data being put into VIA without the last vector being completely drawn).
A very simple solution – which does work – go to scale 7 and draw everything with that (or accept the loss of 2 cycles – which results in a frame cycle loss of nearly 1000 cycles – which I can NOT accept).
Currently ALL sprites in Vectorblade appear to be shrunk by about 20% – which is (pardon me) SHIT!
I will now start editing all sprites again. I don’t know how long this will take me. It is a boring, dull, damn unnecessary job, which I loath.
ARRRRGGGH!
While these are very interesting test results.. yes, this does sound extremely frustrating!
I’m currently working on a talking face animation with text/voice as a side project in Vide that may become a part of the main game project I’m trying to create. Once I get it done and a couple people can run it on real Vectrex hardware aside from myself, we’ll see if I run into the same horse shit!
ah the quirks of the vectrex, isn’t that why we love it? 😉
I wonder if the original designers of the Vectrex ran into similar issues. I guess they must have done lots of programming experiments on how to control the beam and how to draw vectors already while they were still designing and changing the hardware. In system design, BIOS routines are usually compromises and the result of trying to find a safe way to make things run independently of certain hardware details (and thus they are mostly less performant). Do we know anything about this part of the history of the Vectrex?
I’m sure capacitor age and degradation level also comes into play with this.
Well – certainly.
But the behaviours mentioned are not related to degradation – these are behaviours which seem to be “natural” for some Vectrex with seemingly slightly different hardware.