
A while ago I had a friendly discussion, whether a game like Donkey Kong is possible on a Vectrex.
(No, I don’t intend to build a Donkey Kong clone – my excercises here are purely accademic)
The general question was, can the scaffold, that is the base of the frame be displayed in a timely enough manor, that a game in about 50Hz is possible.
The first very straight forward try was – draw the thing in Vecci – and look what the cycle counter says when you “auto” run it:
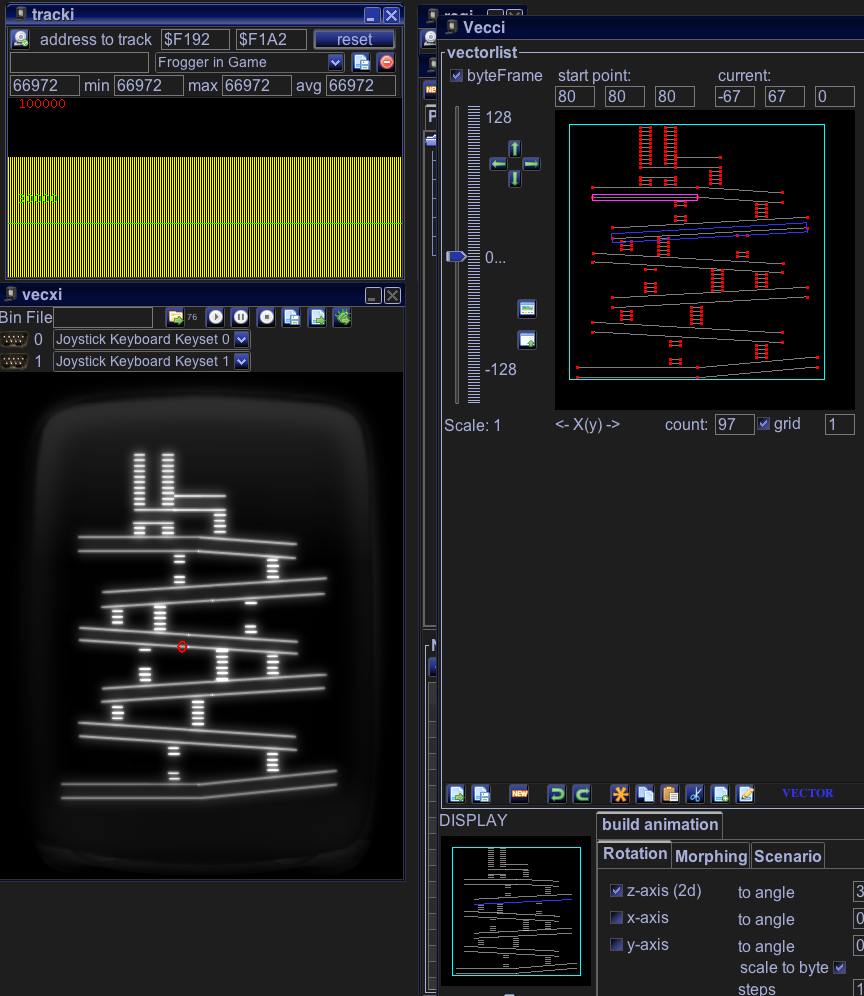
Well it LOOKS ok in the emulator but if you peek at tracki – you notice that screen refresh rate is about 23Hz (66000 cycles) which alone is really terrible, but there also is no Kong, no Mario, no Princess, no hammer and no barrels. If you would add these things it would not only be terrible, it would be really shitty!
Soooo…
While this was a very EASY approach, perhaps we should step back and think a little about it.
Lets first do a bit of “math”, from experience I’d say every “sprite” might take up to 1500 cycles to handle, some more some less, but lets take 1500 as an average.
We have following “sprites”:
– Mario
– Princess
– Kong
– two hammers
– 3 barrels (or more?)
– 3 flames (or more?)
We are ignoring the “score” and the “lifes” and the “level” (also the HELP) for now. I’d say the barrels and flames might take a bit less than 1500 cycles – so to keep everything within 50Hz (30000 cycles) – we should draw the above in about 15000 cycles.
Geee – that is a tough one. Only thing we have to do is shorten it to over a quarter of the time. Easy peasy…
There seem to be in general two different entities:
a) the bars that make up the scaffold
b) ladders
Bars are “large” vectors, and ladders consist of many small vectors, perhaps we can use that to our advantage. Using one draw routine (as the drawSync autogenerator does) prints every (EVERY) vector with the same scale. And as we all know – scale is time. Large vectors – take large amounts of time. And if we mix large and small vectors – and all vectors take the same amount of time – than also the small vectors take much time.
So let us do the “divide and conquer” routine :-).
BARS

These are the bars alone. That does not seem SO bad – apart from the fact, that the bars alone take all the time that we are allowed to take for everything.
Now I press “Isidro All” – which optimizes the vector list, which reduces the cycles to about 10000. Nice!
While I examine the vector data – I see that there are a couple of vectors which are longer than 127 “pixels” – ouch. That is bad, the autogenerator makes at least two vectors from each of those – what else can he do – vectrex is an 8 bit machine.
Through experimentation (and vecci) I find that if I divide every vector by 1.52 – than I will have a maximum length of 127. Now each vector will be drawn as ONE vector. To compensate the size I will use a scalefactor of $c0 instead of $7f. But sometimes even a larger scale is better!
For the “drawSync” this did not give me a real speed increase. But now I am able to use another generator option, which might be better.
CODE EXPORT
Code export – as the name suggests exports the vectorlist as CODE, not data. It usually produces big fat ugly code. But in this case it might come handy. See, the whole scene above is actually a “fixed image”. Nothing moves, nothing is ever changed. You might say it is a background image of the game.
Ok, by pressing code export – we generate code that uses about 8900 cycles – jupee! We are getting faster!
Now we have to enter the think – tank again.
What does the generated code do?
There are a few distinct sections:
– move somewhere (code block)
– draw something (code block)
– move again (code block)
– etc…
The complete image is drawn in one go. This has several disadvantages – mainly 9000 cyles for one list is huge – and drift will be visible. We will remedy that shortly…
Also – now… we still have our large vectors – because of these the scale factor is still $c0 – which is still HUGE.
If you look at the image you will notice, that each “bar” consists of two parellel vectors, which are “connected” by a move vector.
A SMALL move actually!
Now – what we are going todo is – is optimize the auto generated code. For readability reasons I replace those code blocks with macros.
I replace the “in between moves” with moves that only have a scale factor of 12 (instead of $c0) and increase the strength accordingly (factor 16).
Also we will draw each bar “seperately” – not after another. This means after each bar we go to zero, which will give us a much more stable image – but the nice effect is also it is FASTER.
Since with a scale of $7f (from the middle) we can reach the whole screen! And $7f is quite a bit smaller than $c0, 65 cycles actually within 65 cycles we can easily do a zero ref. This is cool – we are faster AND more exact!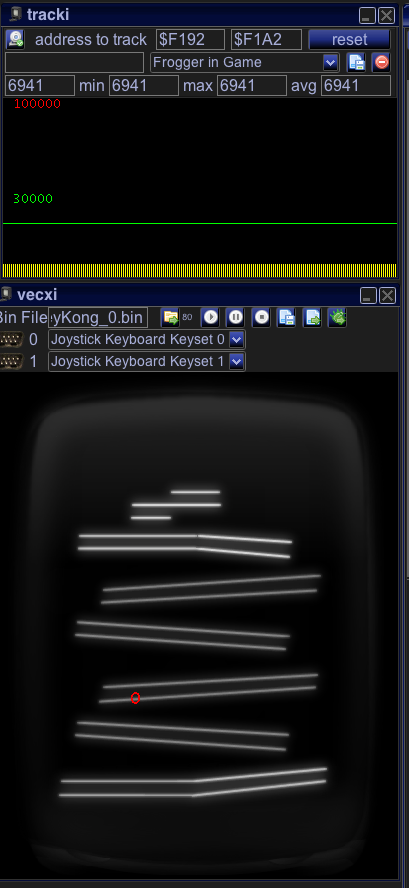 “Code” block… highly macroed!
“Code” block… highly macroed!
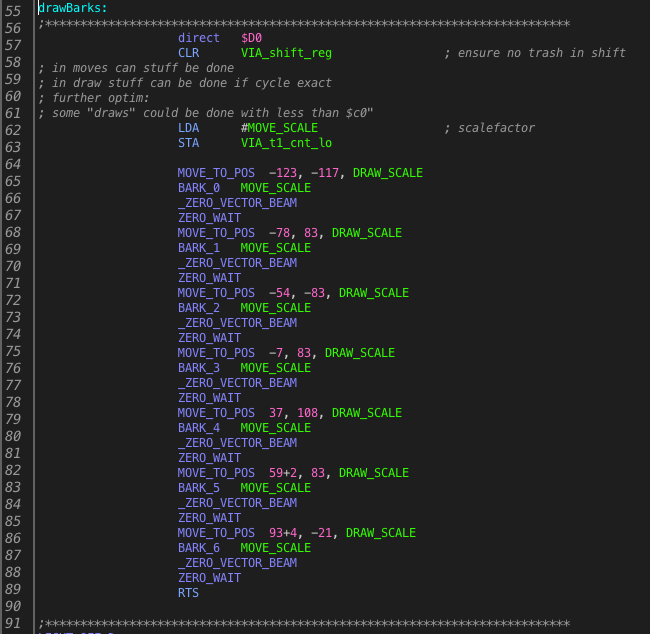
Using all that “magic” -> results in less than 7000 cycles. While I could probably squeeze a few cycles more out of it – I’ll let it stand at that, start looking at the ladders.
Ladders
I tried several options that Vecci represented, like smartlists (which was difficult, since the delay is implemented by using NOPs, and doing NOPs for a scale of $c0 resulted in branches out of bounds etc). Sync lists etc… but everything out of the box was quite slow (> 40000 cycles).
Thing is, while the ladders consist of small vectors – the positioning uses a larger scale – and the automatic routines – use ONE scale not several.
So the only sensible thing do was, to split all ladders up and do each ladder on its own, not one large list.
Each ladder must be placed seperately using one scale factor (move scale) and drawn using another (draw scale).
So 15 seperate ladders – that is it.
Once I accepted the fact, that I had to draw them seperately anyway – I sort of “left” vecci and started to code.
A ladder (like above) is quite a simple thing, it consists mainly of three entities:
- draw one step left
- move a certain amount up
- draw one step right
These three steps repeated in the right order “draw” every ladder. I programmed an optimized macro for each step, and “applied” those.
So e.g. the bottom right ladder looks now like:
 The result:
The result:
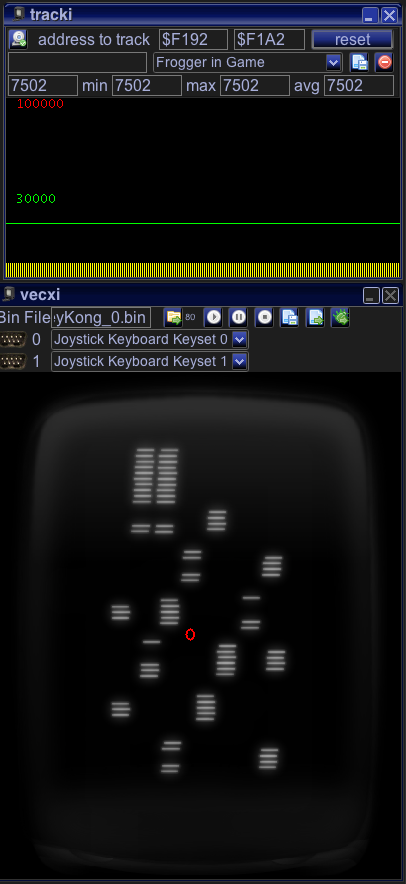 WOW – cool 7500 cycles!
WOW – cool 7500 cycles!
Sure the ladder could be a bit “straighter”, and the optimized drawing takes some toll … but hey – it still is a vectrex!
(And hey, there might be some better coding – I put this together in about 4 hours…)
The complete image of the level (as shown in the first image on this blog entry) is displayed in 13540 cycles. The image is ROCK SOLID, since every ladder and every bar is placed from zero. No wobble at all, and probably enough time to spare for a complete game.
Also:
– there are 22 moves with a scale of about $7f – within these (>100) cycles you can do stuff which does not influence VIA
– there are 19 vectors which are drawn with a scale of $c0 – within these (>160) cycles you can do stuff which does not influence VIA
(but you must use in each round exactly the same amount of cycles, otherwise the vector ends will shake)
Also 2:
Slightly more optimizations might be added, like:
– all moves could be done with highest Move value = -128 / 127, than the scale could be optimized to that strength
– there are some smaller BARS, these could also be drawn with a smaller scale (and higher strength) – look at BAR 6, and the bars that halfway change rise
– the ladder injards might be optimizable further (either y or x is always 0, probably can take advantage of that somewhere)
So – anyone who wants to do a “donkey kong” for vectrex… I think it is very well possible.
If you want to look at the code… I produced, download DonkeyKong.zip (40kB) and open the project in Vide.
Awesome as usual Chris
🙂
Mama Mia! What a glorious post! 😀
Speaking of porting DK arcade code to 6809 (Coco3), a good friend of mine, pointed me to this: http://users.axess.com/twilight/sock/dk/index.html
May be useful? …since I am not a programmer, I can’t tell for sure but certainly is an interesting read…
As said… I am not planning on doing a Donkey Kong.
But I know of the site you posted… read it all some time ago! Great stuff!
Great post, it’s a really good master class on how to optimise, and shows it’s just solid engineering and not really rocket science, but does need commitment (and time)!
Thinking about performance, and the link with the CoCo, has anyone considered putting a 6309 into the Vectrex? It looks a drop in replacement and in native mode will run some instructions faster. I suppose if you’re going to the trouble of swapping the processor, then you might as well use the native features, which you can swap in and out of by software switch. The 6309 will also run a faster clock, maybe 4MHz+, and assuming the other chips will take it, you could double the number of cycles available per 50Hz frame. Maybe I’m just dreaming… 😀
I think Jason “thought” about the 6309.
The pure MHz+ might not be the great speed increase – since the Vector hardware is one restricting factor. The timing here is important and (for example) 200ns measured with a 4Mhz CPU is the same as 200ns measured with a 1.5MHz CPU :-).
Also VIA and PSG might not be very happy about different clock speeds either.
Pure/simple overclocking was done by Jason – see: https://www.youtube.com/watch?v=s4lbViDDlUQ
I have nearly doubled the clock speed of the vectrex before i can assure the via is the weakest link at a higher clock it skipps data . For example an heavily overclocked vectrex will only display vcex on the boot screen instead of vectrex
Yes, I appreciate you might not be able to draw lots more vectors, but you’d have time for other stuff like game logic. I’m sure maybe 20,000 extra cycles would come in handy, and you might get even more as the 6309 can do the some operations with less cycles. Also, the VecFever MAME shows the limit is not far behind a full size arcade monitor anyway. As a drop in replacement, a 6309 could be a good performance boost – games could be written for 6809, then maybe also optimised for 6309, a bit like Xbox S and X 👍🏻