Long time – no post. I am still in the thrall of my new powerfull computer. Having played some games not possible before. Example: nearly 500 hours of ARK.
Dispite of that, once in a while I get some itches and do Vectrex or Vectrex related stuff.
Stuff that need no attention for a greater length of time, but can sort of be done in between.
E.g. I am cleaning up the Vide code to do another release, I fixed most open tickets, and merged 2 code changes from other people (scaling problem in windows, and support of VecMulti Dev mode).
But the thing I would like to write a little bit about today is Bloxorz, a game done by Frank Buss (https://frank-buss.de/vectrex/). There was a kickstarter campaign about it (kickstarter), but that was already about 3 years ago. As I understand it there were several problems in between… but Frank has assured us, that he will finish the game.
Actually as I understand it, it is about 90% done – only a few finishing touches are missing, one being the completition of the arcade mode and the other thing something about performance.
One thing I really like about Franks way of work is, that he is very “open”… all sources to Bloxorz are on github (https://github.com/FrankBuss/bloxorz), so you can have a peek at them at you leasure.
I have been a beta tester of bloxorz “back in the days” – and I also already implemented some assembler code to speed up the display. But the later was dropped due to easier development, Frank always thought to get back to it – but it was not on the top of the priority list, which is totally correct, first finish gameplay – than do optimization.
Anyway…
Last week I looked again at the repository, checked out the sources and compiled them and everything worked out of the box, 34 levels are implemented and playable – nearly the complete game.
(although Franks “PIC” bankswitching is not yet supported by Vide – that was no real problem)
Sooo – here I was, a little bored, not wanting to tame another lizard, and looking at vectrex code again and vectrex code, which at least in some of the more crowded levels, flickered like hell.
I could not help myself but to think – how far can we go optimizing this – and can we display every level in 50Hz?
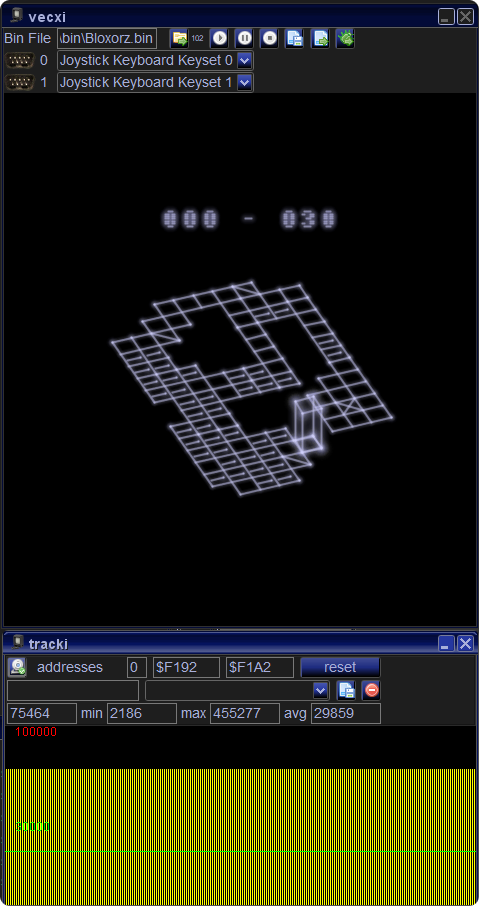
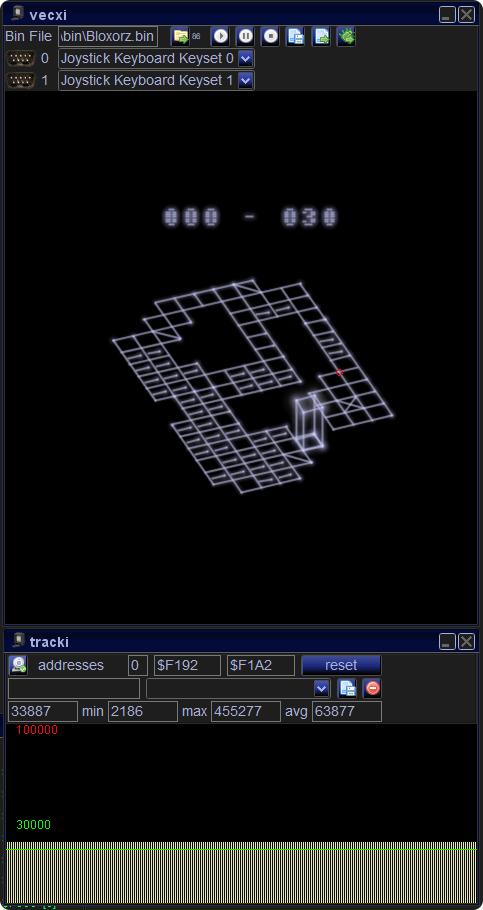
In the image you see “the worst” level I could find – Level 30 – which consists of about 100 vectors (sometimes more, sometimes less – there are switches).
Tracky tells us, that it needs about 75000 cycles to display – which is about 20Hz.
I needed to look at the code at this point… Here is in short words how a level is displayed…
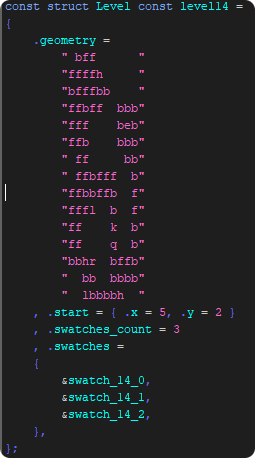
In the image you see how the level data is kept within the code. The ASCII map is investigated by a set of functions:
– void setupX()
– void setupY()
Which build horizontal (void setupX()) and vertical (void setupY()) lines, such that only “complete” lines are drawn (not every square seperately). This is already a very good optimization!
The levels line information is only processed at the beginning of each level (and upon switching) so that one might say, each level is compiled to a data structure upon entry and thus optimized and cached, rather than interpreted with each display round – another great already implemented optimization!
The cached lines consist of 2 pairs of coordinates, line startpoint and line endpoint:
int8_t lineX0[MAX_LINES];
int8_t lineY0[MAX_LINES];
int8_t lineX1[MAX_LINES];
int8_t lineY1[MAX_LINES];Those coordinates are stored as absolut coordinates.
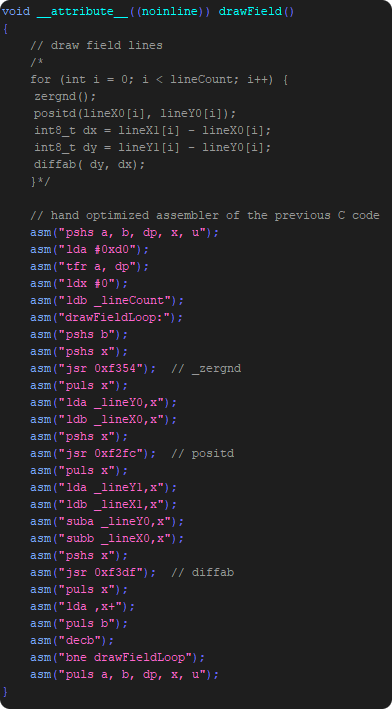
In the next image you see the original code, in the comments the “C” version and the “optimized” assembler version.
I must put optimized in quotes – because I honestly think this is a preliminary assembler version which is not really optimized and which acts as a placeholder.
I would think (I did not check) that probably this is gcc generated code and not in any way faster than the “C” version.
But the advantage of the code is – it is readable and one can easily follow what the code is doing…
There really only is a loop, which draws each line seperately (zeroes in between and positions each starting point).
So a field with about 100 lines…
- resets to zero 100 times
- positions the beam 100 times
- draws a line about 100 times
What you not directly see… the positioning is done with a scale of $7f as are the lines being drawn.
Also note, that Frank follows the naming given by the original developers rather than the naming invented by Fred Taft and Bruce Tomlin 🙂 [which due to my “early involvement” I use – since I didn’t have access to the original documentation].
Optimizations
Now lets start … what can we do to make all that a little bit faster. One step after another.
Reset0Ref (zergnd)
Was the first thing to catch my eyes (probably because the code starts with it).
There are two issues I have with it:
- Reset0Ref()
Is a “complete” zeroing. Most of the time you only need to reset the integrator values.
With complete I mean:
It does not only zero the actual integrator values, it also zeros the integrator offsets and it zeros the SHIFT register. These additional zeroings which are not needed take 31 cycles. Times 100 = 3100 cycles.
If you only want to zero the integrators – use the function Reset0Int() (it still also zeros SHIFT). - To Zero the beam, all you need to do is store one value into a VIA register:
ldb #$cc
stb <$d00c
This only takes 6 cycles and 4 bytes of memory.
jsr Reset0ref
takes an additional 13 (!) cycles [not included the cycles mentioned above] – but uses one byte less of memory.
To save 1300 cycles, I will always “waste” one byte of memory!
Thus – replacing in the above code the:
asm(" jsr 0xf354"); // _zergndwith:
asm(" ldb #0xcc");
asm(" stb *0xd00c");saves nearly 5000 cycles – and for all our purposes does exactly the same!
Data storage
Whenever I see something like (or similar):
asm(" lda _lineY0,x");
asm(" ldb _lineX0,x");I shudder inside – this is probably a sign, that I have programmed vectrex for too long. If I see something like above I automatically think:
!!! asm(” ldd _lineY0,x”); !!!
(or better still “ldd ,x”)
The data “structure” Frank used is very simple and intuitive – one array for each value of the coordinate:
int8_t lineX0[MAX_LINES];
int8_t lineY0[MAX_LINES];
int8_t lineX1[MAX_LINES];
int8_t lineY1[MAX_LINES];
While this is self explanatory – it is also “evil” – you cannot access both coordinates with a single load. Soo… what I did is just build one large array:
int8_t line_y0_x0_y1_x1[MAX_LINES*4];
(I could also have built and typedef’ed a structure – would be better readable – but somehow I didn’t.)
Several lines further down in the display routines following appears:
asm(" lda _lineY1,x");
asm(" ldb _lineX1,x");
asm(" suba _lineY0,x");
asm(" subb _lineX0,x");I ripped that out – this calculates the delta of the absolut start position to the absolut endposition. Since we “precompile” the line information anyway – we might as well do that calculation within the preparation.
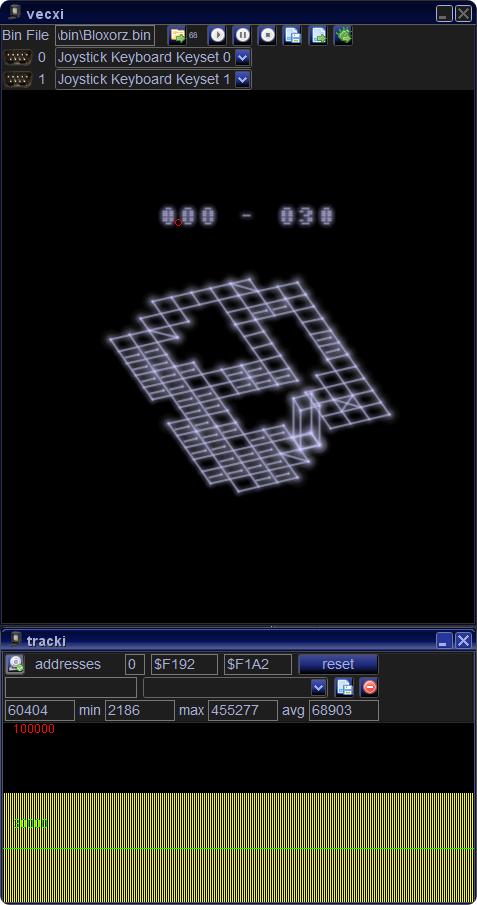
The corresponding (including small other changes) display function now looks like:
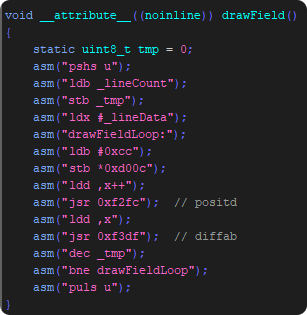
These structural changes again save more than 10000 cycles(!).
As with “Aklabeth” optimization… all this is nice – but we have over 30000 to go – what next?
Replace BIOS functions
Usually the BIOS functions are cycle eaters… we will replace them with inline code.
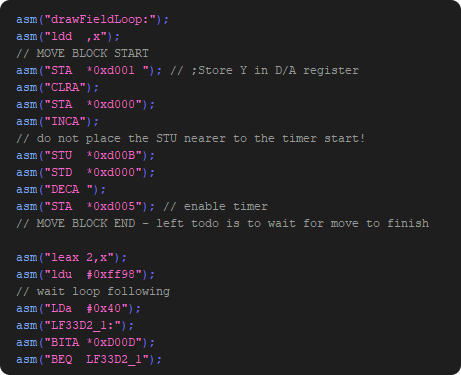

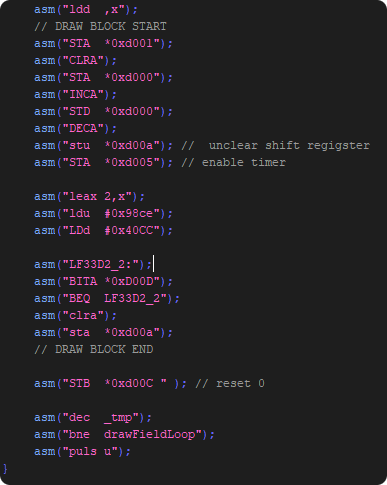
“Inlining” optimized versions of the drawLine and the move_To gives us another 10k cycles.
Scaling
While not obvious from above code – every draw and every move… uses a scale of 0x7f.
Reminder:
With vectrex, lines are drawn using two factors: Strength and Time.
The product of both determins the length of a vector. You can get the same length of a vector with different factors, as long as you reduce one factor by the same amount as you increase the other.
That (scale) 0x7f is a TIMER value – these are 0x7f cycles the beam moves from position A to position B.
Strength is a 8 bit signed value ranging from -128 to +127.
As you can see from above image the grid lines in general are often quite long… but tile drawings are very small. Especially the drawing of those small tiles would benefit largely if they were drawn with a smaller scale (and a larger strength).
The code for this gets a bit lengthier – thus I will not show the code here – if interested go to the Bloxorz github (link above), Frank already included my current code version with the repository.
Anyway in a few words – what I did:
- while building the vector list I check every vector, whether any absolut length is smaller than 64 (or on cranky vectrex a somewhat smaller value, to not endanger cranky behaviour)
- if smaller, than multiply the strength by 2 (and keep staying within the 8 bit range) and divide the scale by 2
- do that 3 times for each vector (so the final vectors might have only the scale of 0x7f / 8)
- change the data to also include scaling information now:
int8_t lineYX_yx_s_dy_dx[((int16_t)MAX_LINES)*5]; - within the display routine – between drawing – change the scale
(With slightly other changes to the drawing routine (no wait loop with $7f movement, but fixed “instruction” waits …))
This results in another 16000 cylces saved!
Delta movement
As of now – each and every line on display gets drawn like:
- moveto position (scale $7f)
- set scale for draw
- draw line (with reduced scale)
- reset to zero + reset scale to $7f
For the grid this is in 95% of the time good, or at least ok.
Knowing that the small lines within the tiles in one “horizontal” line are drawn directly in order – another optimization comes to mind.
If the position of the next line can be reached with the current active scale (and the scale is smaller than 0x7f) – THAN do not reset zero, but do a delta move from the end of the current line to the start of the next line.
This saves:
- the reset zero
- the settle time for reset zero
- setting of the scale
- the movement (time) is smaller (scale reduced)
This comes however with the slight overhead of the need to do an additional check and branch.
Most of the “checking” can however be done during the preparation phase of the vectorlist. We do not even need an additional data field, because we can use an already available field.
The scale as of now can only ever be 0x7f or smaller -> thus the highest bit of that byte is “unsused”.
Also fortunately the highest bit of a byte can VERY easily be checked – if it is set, the value of the byte is negative… so … what we do is – to check within the preparation phase, whether we can reach the next starting position – and if so – we set the highest bit of the scale and instead of absolut start coordinates for the next vector, we store delta coordinates from our current position.
While displaying… we check whether the scale is negative – and if so – we do a delta move, not a reset zero and move.

Ok.
I cheated there. With “just” changing the line structure and the display routine – I was not able to get to display in 50Hz. I was short of about 800 cycles – and without (additional) display distortion I was not able to find anything further to optimize within those routines.
I did change one additional routine – the display routine of the “player” – the block!
I did a little Draw_Vlp routine in assembler, and changed the block lists to use a smaller scale. That got me the needed cycles.
But it is done – as of now – Bloxorz displays in all levels with 50Hz!
Disclaimer:
The optimizations (draw and move routines) were tested with 5 of my Vectrex, one of which is “cranky as hell”. But nonetheless, these optimizations are a touchy affair… It might be, that the display is not on all vectrex 100% correct – these routines have to be tested with as many vectrex as we can lay our hands on.
The optimization itself has different “levels” of efficience (or deficiencies), I am certain that 20 of the levels display 100 percent correct. With the other 14 there may be very slight offsets to some of the drawn vectors, for which I have found no solution to get rid of 100%, since a solution on one vectrex corrupts the display on another vectrex.
On my vectrex I found all displays reasonably correct – but not always 100% perfect. I was willing to accept very slight offsets as a sacrifice to be able to display in 50Hz and wobble free – but in the end Frank has to decide what he wants his game to look like…
The (possible) inaccuracies are the result of two facts:
- scale * strength <> (scale/2) * (strength*2)
While in general it is true, that the overall length of a vector is calculable by scale multiplied by strength, it is not 100% true if you enter additional modifiers.
There are ever so slight differences, these differences might even be individual vectrex related.
(additionally if scale is an uneven number – there are rounding differences) - The “SETTLE” time and various other aspects of the analog hardware differ from vectrex to vectrex, as there are:
– zeroing
– integrator charging
– integrator offsets
– drift
– switch time for blank
– …
While the differences are in general VERY small – there ARE differences!
Additionally the values (waits) I use might still not be globally bullet proof.
29916 cycles…that’s really close to the limit, what happens if someone moves the joystick, will it then flicker? 🙂
Thanks for the explanation, as I’ve been working with SmartLists recently, it seems quite familiar. However, there is quite a mental jump required, from using SmartLists/inline VIA control code, to really understanding what’s actually going on at VIA and DAC level. I haven’t had the courage to really attempt groking it yet. But I will get there eventually!
I will give a plug for SmartLists from VIDE, ROM is now plentiful, so using SmartLists is well worth the extra effort to utilize, though some experiments are needed to get a good result. It would be nice if they were pre-assembled like the BIOS functions and could be linked in by the assembler, but of course then they’re not optimized to the game-specific vector lists needed, so you’d have to have multiple pre-assembled versions using different parameters.
Maybe you could do a short video on just VIDE SmartList functionality or, even better, a video on exactly what the inline code is actually doing, though that might score people away 🙂
Yea – it is pretty close – but “enough”.
The main “joystick cycle eater” is the routine that actually reads the joystick position, and that one is called every round anyway.
In “C” one can use preassembled library files. In assembler one usually does not, there is no “linker” stage.
I think in this case it is better and an advantage to use template files of code and fix them for your specific needs.
The only thing I would wish for, would be a more powerfull way to examine which parts of the template actually need to be included and which not, so one does not assemble code which never gets referenced.
–
I am a bit relcutant to actually document/do a video about VIA programming – because it is sooo touchy. It works perfect on one vectrex while doing strange things on other vectrex. So for the specific watcher what I say might actually be wrong. There are still phenomena discovered which we do not know of – but only ever occur in 1 of 1000 vectrex.
See the revision history of vectorblade …
Nice read! Thanks a lot!
One quick note: The “ldd instead of lda + ldb” thing can easily be achieved on C level without needing inline assembly by defining a proper data type, i e. a union containing a 16 bit int and a struct which consists of two 8 bit ints.
I’ll give it a try in 2 weeks when I’m back home and report back. Thanks for the detailed write up!
I just modified my RESET0REF macro to just do the 2 instructions above and everything seems to work the same, thanks for the cycle saving tip.
Always a pleasure to read about your optimisation efforts.