World changer
Ok. We reduced the world map draw by 20000 cycles, sounds good – but we still must reduce it by another 35000 cycles.
Such a thing cannot be done by doing little things – here we must change something substantial.
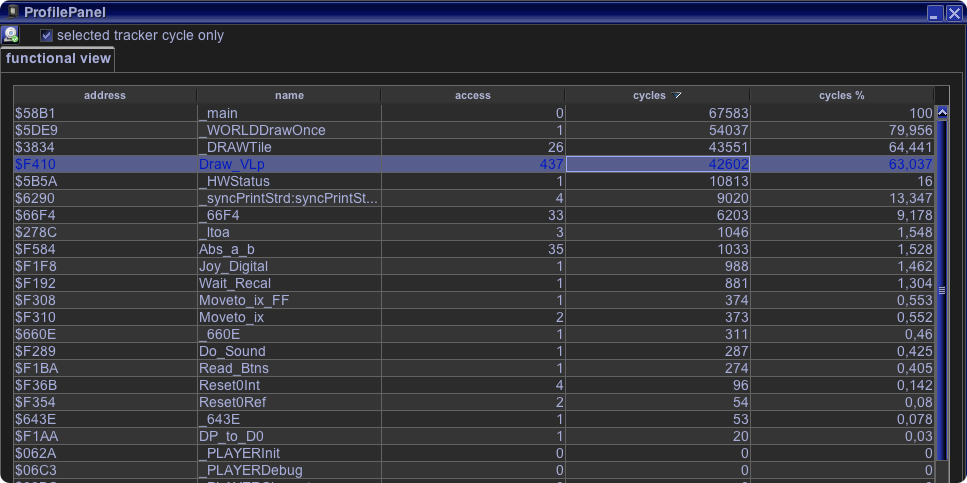
For confirmation I take a look at the profiling of Vide – and unsurprisingly the DrawTile() function uses 43500 cycles and within that 42600 cycles to draw our vectorlists of the Map (the stringlist optimizations were not done yet – as you see the current string takes about 9000 cycles – so we are better than described above – yeah!)
The world changer will be a different approach to drawing the tiles.
Surprise surprise!
The fastest known functions to draw something is specific optimized draw code for each list. But this takes heaps and heaps of memory.
The next best thing are smartlists – while initially these also have a huge memory imprint, it does not grow with “usage”. So I will try to use smartlists for this – thing is these things are pure assembler – and for that a DIFFERENT assembler than the usual one which is used with GCC.
But! we have a very usefull tool at hand – VIDE!
- Vide can create smartlists from any vector drawing
- Vide can output these list as “runable” code, which means it is a ready to go vectrex binary with everything we need – in assembler
- Vide can translate the usual assi code (Kingswood compatible) to as6809 assembler code with 2 clicks on two buttons
(after a little bit of cleaning up – we only want the smartlist routines and the actual smartlist, not the vectrex header and not the main loop) - these assembler sources can be copied into the “C” src directory and are automaticaly assembled and linked with the “C” program
- of course the passing rules of parameters must be used by your assembler function (but in this special case – there are none!)
TWO!
things have to be done however in the current Vide version (I’ll try to fix this with the next).
a) the linker must be made aware of the DP register settings – otherwise it utters warnings or even errors. This means before the first function but WITHIN the area:
.setdp 0xd000,_DATA Must be inserted!
b) If you are lazy like me and do not properly prototype your assembler functions with the correct register usage settings – things might get ugly.
Since I AM lazy – I must save the “U” register (at least) when calling the assembler function – so at the start there must be a “pshs u” and at the end a “puls u”.
(Actually – with smartlist export there is one other problem – which I will probably fix with the next Vide version. The actual vectorlists generated look like:
Mountainlist
db -$03, -$05, hi(SM_continue_d), lo(SM_continue_d)
db $00, $02, hi(SM_startDraw_d_y0), lo(SM_startDraw_d_y0)
The AS6809 can not cope with these “hi/lo” constructs the above lines must be written as:
Mountainlist db -$03, -$05 dw SM_continue_d db $00, $02 dw SM_startDraw_d_y0
For the time being this must be done manually)
Example
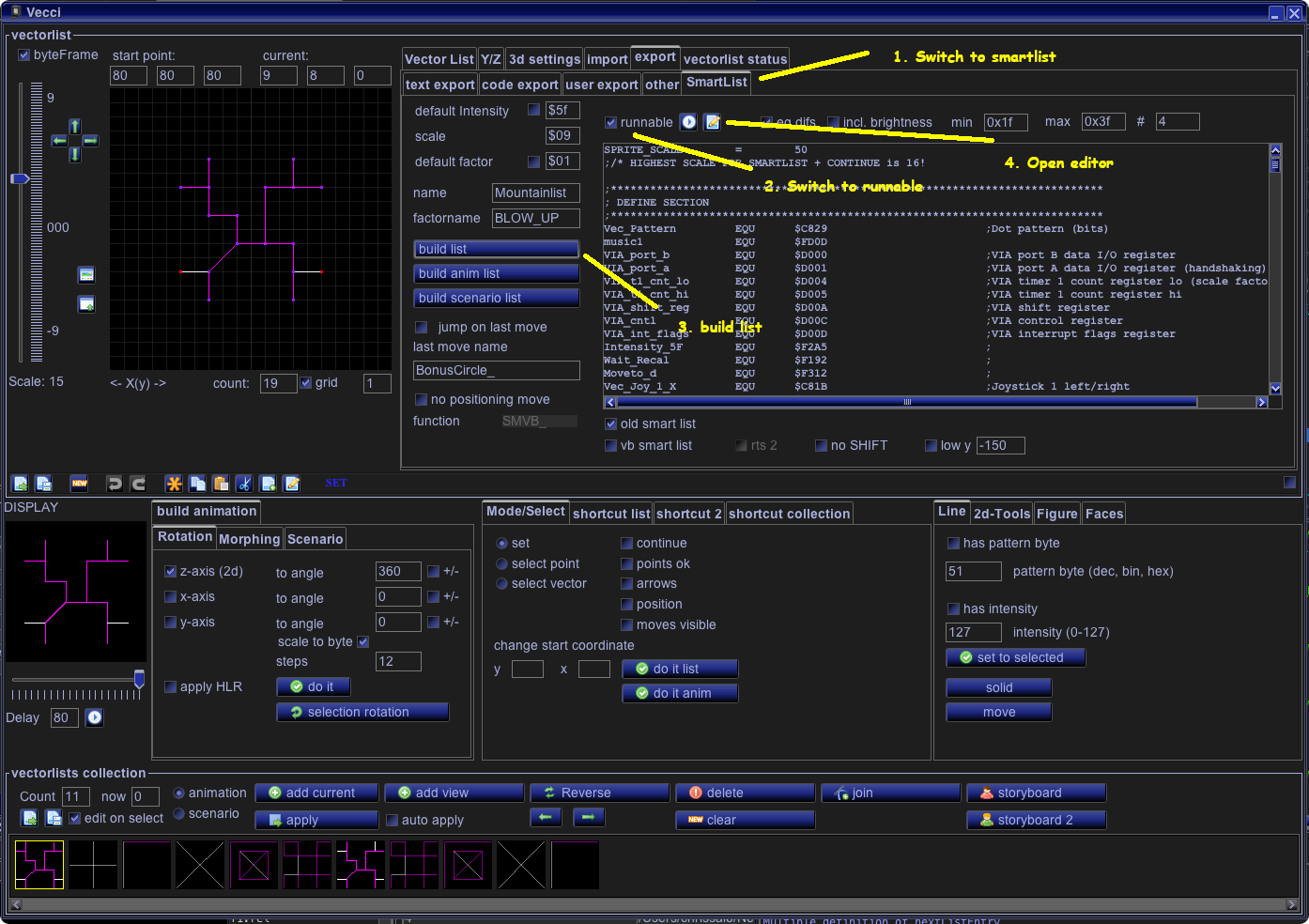
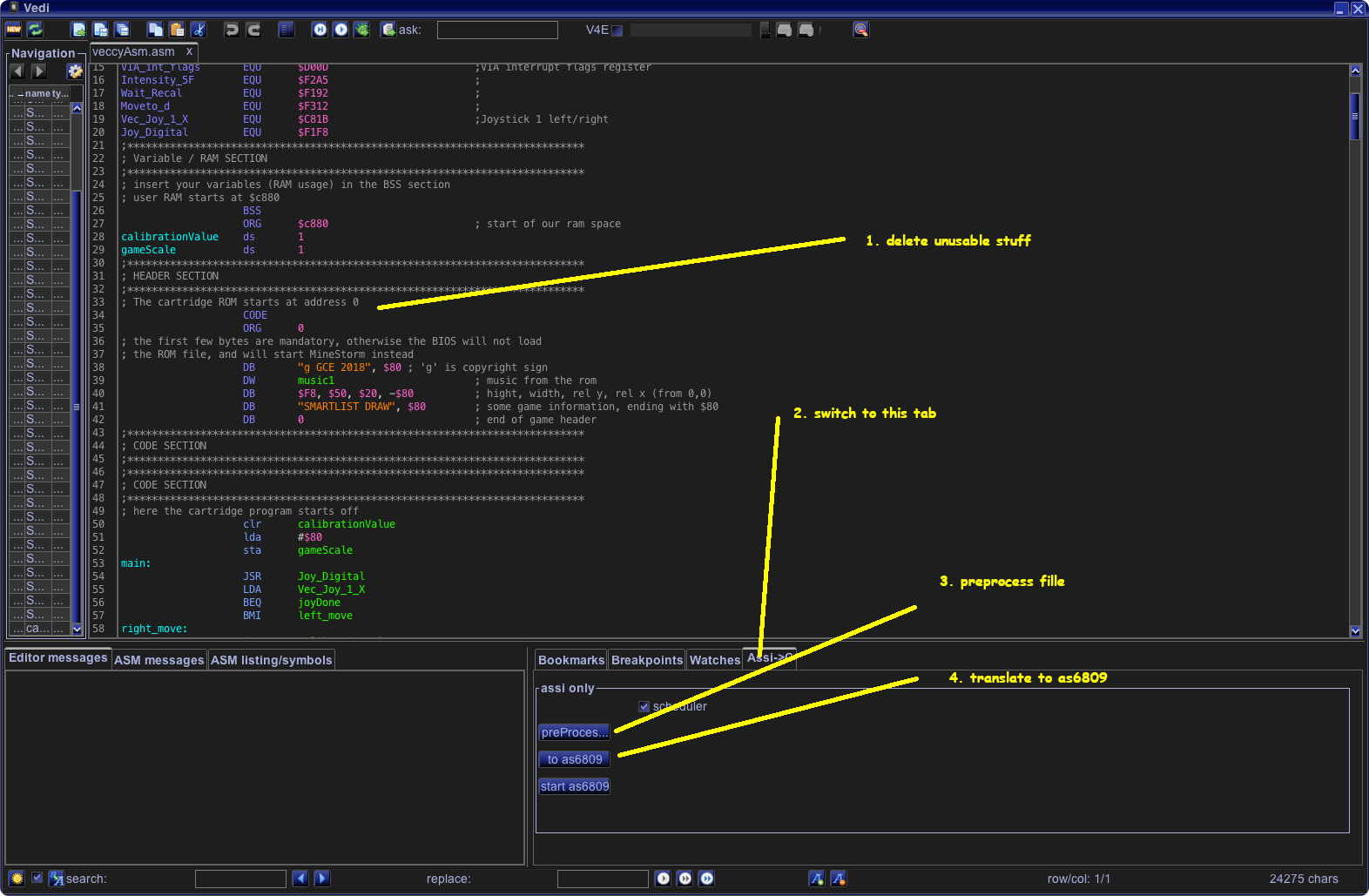
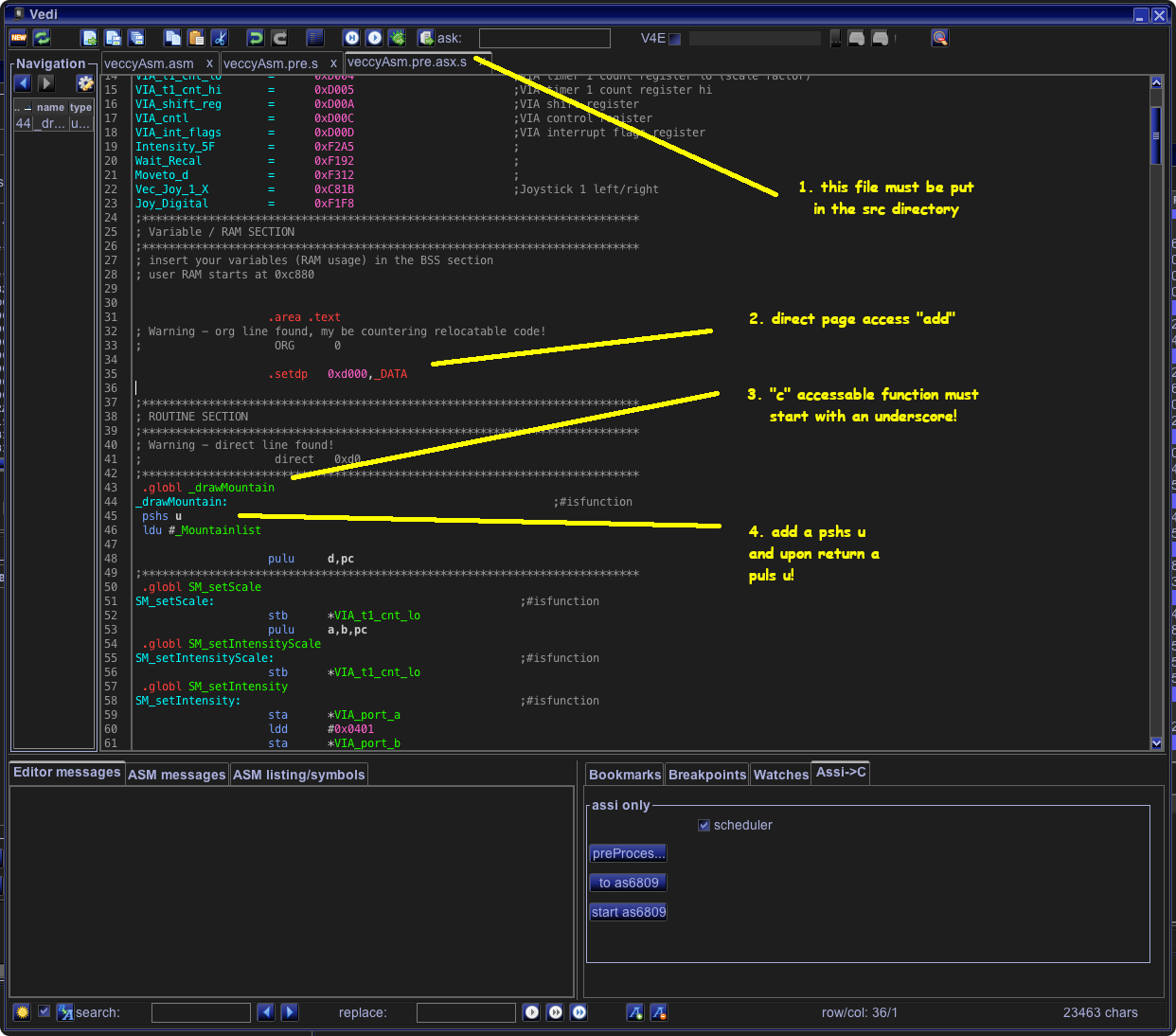
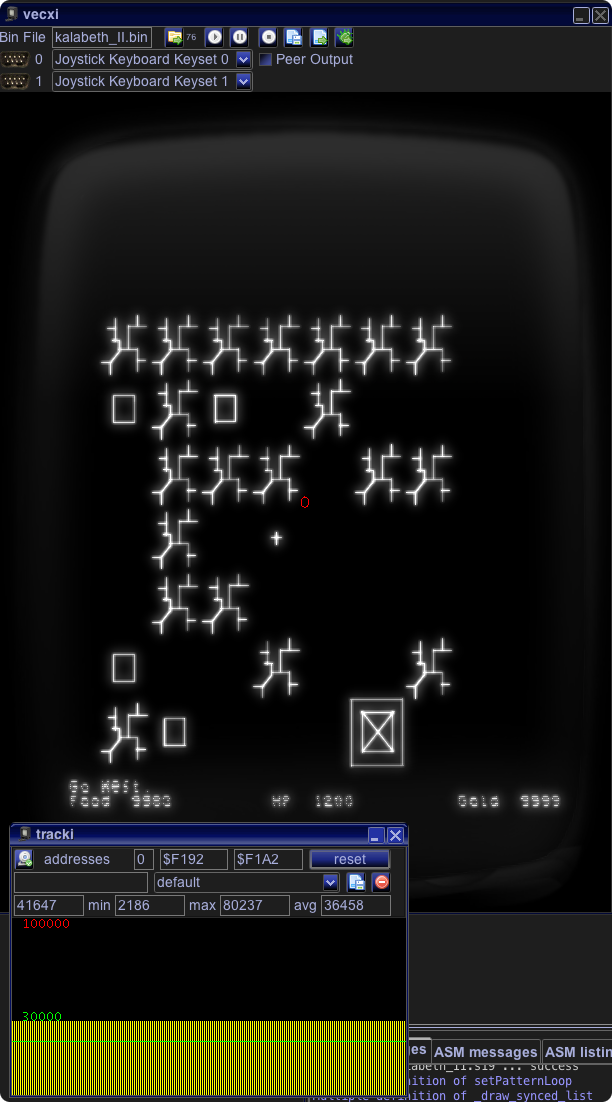
Ok. Yeah. I get it. You think that was complicated.
Hm. I am so into Vide – and doing those things… once you have done them a few dozen times, it seems really easy!
Anyways… lets look what we have got now.
Changing ONLY the mountain printing from Draw_VLp to smartlist – saved us over 25000 cycles. THAT is a world changer!
Let us see – we started with about 85000 cycles, so far we have done:
- 8500 for “string” changes
- 10000 for “C” changes
- 25000 for “Mountain” changes
= 43500 so we display now with about 42000 cycles – we need to find at least another 12000 cycles. Lets move on!
Well … there is a very logical next step – updating the other world objects to smartlists. But as you can see from the above image – usually not really many of them are displayed… nonetheless – lets do that.
- 2000 for “other map” changes
Not enough.
Now… let us think about Vectrex Frogger. What changes did Vectrex Frogger bring into the Vectrex world?
Doing stuff within the “move” time of vectors!
The current draw part looks like:
if (*toDraw_p != WT_SPACE) { dp_VIA_t1_cnt_lo = 0x60; // scale Moveto_d(y,x); y1--; VIA_t1_cnt_lo = 0x60/4 +3; // scale DRAWTile(*toDraw_p--); dp_VIA_cntl = (unsigned int)0xcc; }
As one can see there is a Moveto_d(), some code and than the drawing. The “some code” stuff can be done DURING the move.
Now we leave a little bit the comfortable “C” – “let us call a subroutine” attitude, and do it ourselfs.
I am not in the mood to do an actual piece of assembler code, since here “C” does its job very well. The same code as above with the “beginning” of a Moveto_d():
if (*toDraw_p != WT_SPACE) { dp_VIA_t1_cnt_lo = 0x4d; // scale // Moveto_d(y,x); dp_VIA_port_a = y; // y pos to dac dp_VIA_cntl = (unsigned int)0xce; // disable zero, disable all blank dp_VIA_port_b = 0; // mux enable, dac to -> integrator y (and x) asm(" nop"); // cranky vectrex "wait asm(" nop"); // cranky vectrex "wait dp_VIA_port_b++; // mux disable, dac only to x dp_VIA_port_a = x; // dac -> x dp_VIA_t1_cnt_hi=0; // start timer y1--; DRAWTile(*toDraw_p--); dp_VIA_cntl = (unsigned int)0xcc; // enable zero, enable all blank }
The idea is to finish the move at the last possible moment, to catch as many cycles as possible. For that to work out best – I plan to finish the move within the “DRAWTile()” function – right before calling the smartlist.
But as it turns out – this is not necessary!
See – Moves in vectrex relation are funny things… if you give them enough time, they finish moving on their own (timer driven). So – if you can ensure that always enough time passes – you do not NEED to concern yourself with finishing the move!
And as it turns out – in our case “C” is slow enough (once this works FOR us 🙂 ) – that the move is ALWAYS finished befor we call the smartlist!
Long story short:
- 4000 for “in Moveto()” changes
DONE!
Now we refresh in und 29000 cycles – like shown in the first image!
Ahhh. Yes. You got me there. The math does not work out yet. We should do another 6000 cycles. But here I cheat. The other 6000 cycles were actually not optimized within the “world” display – but within “housekeeping”, the main loop and other things. I might mention them later. But the “pure” world display is now as optimized as I wanted it to be. It might be, that there are more things possible – but I reached my goal. The world displays with lucky number 42 in all cases UNDER 30000 cycles.
If you tell me a lucky number where that is not the case… I’ll happily go in search for more optimization of the world display, but for now I am done!
to be continued (the dungeon)
Ceterum censeo… 😉
Better use “asm volatile” instead of just “asm”. Inline assembly instructions are black boxes to the compiler, and compiler optimizations are free to move those around, or, in some cases, even to leave them out completely. So, the inline assembly might not end up at the location you want it to be.
I learned that the hard way, and such “bugs” are a nightmare to find, unless you have a clue about what is going on. Using the “volatile” qualifier is one way to prevent this. Another way are memory barriers. Best way is to use both:
asm volatile (“” ::: “memory”);
This will ensure that your asm instructions will end up exactly between C statements 1 and 2. Compiler optimization is forbidden to change the overall order, or to remove the asm black box.
Thanks for part 5 of this interesting journey!
Cheers,
Peer
Oops, some parts of my code example seem to have vanished from my post. Probably because I was using braces, which seem to have some meta meaning in the text editor?
The example should look like this:
C statement 1
asm volatile (“your asm instructions” ::: “memory”);
C statement 2
Hope that this displays correctly now.
Thank you for the correct code.
I checked the asm source whether the “NOP” are at the correct position – but of course you are right, better take the save route!
By now I know you well enough that I was 100% sure that you had checked on the nops 🙂
My comments were rather meant as a helpful hint to other readers. As I said, I learned about the peculiarities of inline assembly the hard way. And because some of the potential future readers of this blog entry could be my students, I though I better mention this here 🙂